2023년 2월에 LLaMA(Large Language Model Meta AI) 논문이 나왔다. 이 글 작성 시점에서 4개월 전임에도 불구하고 그 사이에도 많은 연구들이 쏟아져 이제는 까마득하게 느껴진다. 지금 시점에와서 논문의 리뷰를 하는 것은 애매하기도 하고, 이미 좋은 리뷰들이 많이 있다고 생각한다. 때문에, 여기서는 LLaMA 논문의 내용만을 정리하기보다는 LLaMA를 중심으로 LLM 전반에 대한 고려 요소들을 한번 정리하는 글을 써보려고 한다.

LLM의 성능을 단순히 벤치마크로 비교하기는 어렵지만, LLaMA는 모델의 멀티태스크 벤치마크에서 퓨샷러닝의 정확도에서 13B 모델이 GPT3 175B 모델보다 좋은 성능을 보였다. 그리고 모델의 구조도 아예 공개하고, pre-trained wiehgts도 학술용으로 공개하면서 LLM에 대한 오픈소스 연구를 폭발적으로 가속시키는 영향을 준 모델이다. 이후로 LLaMA를 응용한 Alpaca, Vicuna, Guanaco, Wizard LM 등의 LLaMA계열 모델들과 Dolly, MPT, Falcon 비 LLaMA계열 오픈 소스 LLM들이 경쟁적으로 공개되고 경량화 모델에 연구들도 급속도로 진행된다.
1. Pre-train data
LLM의 성능에 가장 큰 영향을 주는 요소이다.
학습데이터의 경우는 다시 첫번 째는 학습 데이터의 양, 두번 째는 학습 데이터의 구성으로 나눠서 접근해볼 수 있다.
1-1) 학습데이터 양
pre-train 단계에서의 학습데이터 양은 LLM에게 얼마나 많은 지식을 넣을 수 있는가와 연결된다고 생각한다. 때문에 다른 언어의 토큰을 추가하고 Instruction tuning을 통해 어느정도 자연스러운 생성이 가능해진다고 하더라도, 할루시네이션에 매우 취약한 모습을 보인다. pre-train 이후의 학습은 상대적으로 적은 자원을 필요로 하고, 그 학습의 결과에도 결국 pre-train 모델의 성능이 큰 영향을 주기 때문에 학습데이터 양은 매우 중요하다.
GPT3 이후로 모델의 크기를 늘리는 방향으로 연구가 진행되면서 정말 소수의 대기업이 아니면 아예 엄두도 낼수 없었던 LLM 트렌드에서 친칠라(Training Compute-Optimal Large Language Models) 논문은 단순히 사이즈를 키우기 전에 우선 학습 데이터를 늘리는게 필요하고, 모델 크기 별로 적절한 데이터량을 제시한다. 더 작은 크기의 모델이 더 많은 데이터로 학습한 경우가 더 큰 크기의 모델이 더 적은 데이터로 학습한 경우보다 성능이 좋다는 것을 보여주고, 많은 모델들이 언더피팅 되었다는 것을 보여줬다. LLaMA는 친칠라 모델에서 제시한 기준보다 더 많은 데이터로 학습을 시켰고, 7B모델에서도 1T token의 데이터까지 꾸준히 성능이 증가한다는 것을 보여줬다.
최근의 모델 결과들을 보면 300B~800B 정도의 토큰으로 학습한 모델들은 상대적으로 성능이 좋지 않은 경우가 많이 보인다. 상업적 사용이 가능한 비 LLaMA 모델에서 좋은 성능을 보여주는 MPT, Falcon 같은 모델들도 1T token 규모의 데이터로 학습을 했다.
LLaMA의 경우에도 1T~1.4T의 규모의 학습데이터를 사용했는데, 이제는 그래도 LLM이라면 pre-train단계에서는 1T 이상의 학습데이터로 학습해야 경쟁력 있는 성능을 보여주는 것 같다.

1-2) 학습데이터의 구성
또한 실제로 어느 분야의 데이터를 얼마나 학습했느냐도 매우 중요하다. LLaMA의 경우 아래와 같이 크롤링 데이터가 많이 사용되었는데, 벤치마크 성능을 비교해보면 LLaMA(65B)가 대부분 친칠라(70B)보다 좋은 성능을 보여주지만, 역사, 컴퓨터과학, 법률 등을 포함하는 멀티태스크 벤치마크(MMLU)에서는 친칠라보다 성능이 떨어진다. 친칠라는 학습 데이터의 30%가 도서데이터다.
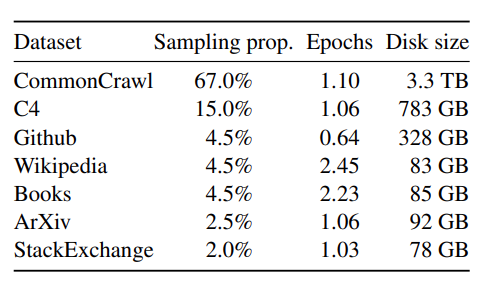
BERT계열의 NLU 모델들에서도 사전학습에 사용하는 데이터가 Fine-tuning시의 성능에도 영향을 줬는데, 원론적으로 생각을 해보더라도 이는 어떻게보면 당연한 내용이다. 데이터의 양이 많은 게 좋다고 모든 분야의 데이터를 단순히 많이 넣는다고 하더라도 결국 모델이 학습한 모든 내용을 공평하게 기억하는 것은 아니고, 데이터의 양이 많아질수록 그만큼 학습 시간과 비용도 늘어나기 때문에 적절한 데이터셋 구성은 앞으로 점점 중요한 부분이 될 것 같다. 코드와 관련된 데이터가 모델의 논리적 추론 능력에 도움이 된다는 것 등 흥미로운 것들도 많이 있다.
2. Framework
LLM은 들어가는 자원이 크기 때문에 최적화와 속도에 상대적으로 더 민감하다. 때문에 다양한 라이브러리, 프레임 워크가 사용된다. LLaMA의 경우에는 논문에서 xformers 라이브러리가 언급되고, 공식 코드에서는 fairscale가 사용되었다. 이 두 라이브러리들은 Facebook AI에서 만들었지만, 이 외에도 일반적으로 LLM의 모델 병렬화와 데이터 병렬화가 잘 구현되어 있는 Nvidia의 Megatron도 pre-train 단계에서 고려할 수 있는 매우 좋은 옵션이다. 또, 분산 학습에서 좋은 성능을 보이는 Colossal AI도 있다. Instruction tuning나 RLHF는 상대적으로 학습 규모 자체가 pre-train에 비하면 작기 때문에 huggingface의 trainer에 deepspeed 같은 방법을 사용하는 것으로 충분한 경우도 있지만 pre-train을 해야한다면 이러한 최적화 이슈에 대해서 더 고민해봐야한다.
위의 경우는 pre-train 단계에서 고려되는 Framework이지만 추론 단계에서는 trition가 좋은 방법이 된다. 꼭 LLM에만 해당하는 것은 아니지만 Auto-regressive의 구조를 갖는 LLM은 디코더 추론에 시간이 많이 걸린다. trition은 속도와 메모리 측면 모두 일반적인 pytorch에서의 추론보다 개선된 성능을 보여주기 때문에 추론 환경은 trition을 통해 구축하는 것이 추천된다.
이 외에도 속도적인 측면에서 Flash attention이 주목 받고 있다. MPT와 Falcon 모델은 Flash attention이 적용되어 있고, MPT의 경우에는 triton을 사용하는 경우에도 사용할 수 있는 Flash attention 코드도 들어가 있다.
3. Position Embedding
GPTNeo의 Rotary Embeddings을 사용하였고, 길이가 2048로 설정되어 있다. 설정값을 바꾸는 것으로 더 늘릴 수는 있지만 성능은 보장되지 않는다. Longformer나 Bigbird 같은 길이와 특화된 케이스가 있긴 했지만 NLU모델에서 512가 표준길이였는데 이제는 매우 큰 모델이 이정도의 길이를 갖게 되었다. ChatGPT의 경우 4096, GPT4의 경우 8K 모델이 언급됐었는데, 23년 6월 기준 GPT 3.5 16k 모델도 이제는 사용할 수 있게 되었다. Position Embedding의 경우 Rotary Embeddings보다 ALiBi(Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation)가 더 우수하다는 의견이 많은데, MPT는 ALiBi를 사용하였다. MPT 모델 중 storywriter는 65k 토큰까지 지원한다.
4. 그 외 모델링적인 부분
그 외에도 모델링적인 부분에서 LLaMA는 아래의 방법들이 적용되었는데, 특별히 새로운 것들은 아니지만 한번 짚고 넘어가는 것은 의미가 있을 것 같다.
4-1 Activation Function
PaLM에서 사용된 SwiGLU를 사용했다. SwiGLU는 GELU와 비슷하면서도 연산이 더 간단하다는 장점이 있따.
4-2 layer norm
GPT3와 같이 Pre-normalization을 사용했다. 허깅페이스의 GPT 구현 코드에서도 GPT 계열의 모델들은 T5 이전의 NLU 모델들과 달리 Pre-normalization을 사용한다. Post-normalization과 Pre-normalization은 Transformer 아키텍처가 나오고 나서 계속 연구되어온 문제다. Post-normalization은 학습이 제대로 진행될 경우 더 좋은 성능을 낼 수 있지만 학습이 더 불안정하고, Pre-normalization은 그 반대의 장단점을 갖는다. 모델 사이즈가 커질수록 학습이 더 불안정해지기 때문에 LLM은 일반적으로 Pre-normalization을 사용하는 것 같다. 이 분야에 대해서는 지금까지도 꾸준히 연구가 되어오면서 다양한 시도가 있지만 LLM에서 메이저한 방법은 Pre-normalization인 것 같다.
layer norm도 T5에서 사용한 RMSNorm을 사용하는데, RMSNorm는 학습 안전성 측면에서 장점을 갖는 것 같다.
5. 경량화
여기부터는 LLaMA보다는 GPT, LLaMA를 포함하여 어떤 식으로 추가적으로 연구되고 활용되고 있는지 다루려고 한다.
LLaMA의 공개 이후 경량화 붐이 일어났고, 이제는 4bit 양자화도 자주 쓰이고 있다. 개인적으로는 4bit까지 양자화를하면 성능이 괜찮은지에 대한 우려가 있었는데, 빅 모델일수록 양자화로 인한 성능 하락이 적기도 하고, 실제로 써봤을 때도 생각보다는 좋은 성능을 보여줬다.
5-1. GPTQ(양자화)
양자화를 고려할 때 가장 무난한 선택지라고 생각한다. LLM의 4bit 양자화를 비교적 간단하게 할 수 있고, 허깅페이스의 모델쪽에서도 TheBloke 레포(https://huggingface.co/TheBloke)에서 활발하게 업로드를 해줘서 그냥 있는거를 가져다가 쓰기만해도 된다. gptq라고 써있는 게 해당된다. 우바부가 WebUI와도 연동이 잘 된다. 양자화 모델을 가장 간편하고 무난하게 쓸 수 있는 방법 같다.
5-2. GGML - LLaMA cpp(양자화)
LLM을 4bit 양자화 후 CPU로 추론을 할 수 있다는 점에서 장점이 있다. 이제는 GPU에서의 추론도 지원한다. 우바부가 WebUI와도 연동이 잘 된다.TheBloke 레포(https://huggingface.co/TheBloke)에서 ggml이라고 하는 게 해당된다. 계속 업데이트가 되고 있지만 개인적으로는 GPTQ쪽이 더 사용하기 좋았다.
5-4. QLoRA(Low Rank)
할 게 많아서 논문까진 다 못 읽어 봤다. Koalpaca 깃허브에 예제 코드가 있다. LoRA로 역전파를 하는 방식이라고 하는데 65B모델을 48GB의 Vram에서 파인튜닝 할 수 있다고 한다. 정말 감사하게도 Koalpaca는 빠르게 새로운 연구 성과들이 반영돼서 보고 배울 수 있는게 많다.
6. 활용
ChatGPT API와 LLaMA 등으로 LLM 사용이 많이 보급되면서 기존의 텍스트 입력->텍스트 출력에서만 끝나던 LLM은 다양하게 활용되고 있다. 생각해보면 많은 판단이나 주문, 요청 등은 텍스트 형식으로 이루어질 수 있고 많은 정보들이 텍스트로 저장되기 때문에 성능이 좋은 LLM에게 판단을 하게하고, 요청이나 주문, 명령어를 사용하게 한다는 발상은 어떻게 보면 당연한 흐름이다.
ChatGPT의 플러그인 기능에서도 볼 수 있듯이 이제는 LLM을 이미 존재하는 서비스들과 연동해서 항공권을 예약하거나 쇼핑을 하거나 하는 것들을 더 편하고 효율적으로 수행할 수 있게 됐다. 국내에서는 뤼튼 같은 회사가 이런 부분에서 선두에 있는 것으로 보인다. 아직 서비스로는 출시하지 않았지만 OpenAI와 달리 한국 회사인 만큼 한국에 있는 서비스들과 빠르게 연계를 해서 플러그인을 출시할 수 있다는 게 강점인 것 같다. 아래는 LLM을 다양하게 활용할 수 있는 유명한 Framework들이다.
6-1) LangChain
다양한 툴들이 사전에 정의되어 있고, 필요하면 툴을 직접 만들 수도 있다. 툴 단위로 정의해서 편하게 활용할 수 있다는 점이 장점이다. 예를 들어 수학 계산을 잘 못하는 LLM을 위해 계산 tool을 만들고 그 tool에 대한 설명을 하면 LLM은 그 툴의 설명을 보고 자기가 직접 답변을 출력하는 것이 아니라 tool을 사용하여 얻은 답변을 활용하는 식으로 더 좋은 결과를 만들어 낼 수 있다. 웹 브라우징을 해서 학습데이터에 한정되는 게 아니라 검색 결과를 이용해서 최신 정보를 활용하게 만들 수도 있다. QA나 검색 같은 것을 간단하게 할 수도 있지만 Agent를 만들어서 목표를 주고 알아서 판단하고 알아서 필요한 것을 판단해서 수행할 수 있게한다는 것이 큰 장점이다. 앤드류응의 강의도 있다.https://www.deeplearning.ai/short-courses/langchain-for-llm-application-development/
6-2) AutoGPT
LangChain은 파이썬 내에서 정의된 tool을 통해 보다 제어할 수 있는 환경에서 작업을 하는 느낌이라면 AutoGPT는 프로그래밍적인 제어권한을 GPT에게 주는 느낌으로 더 많은 작업들을 할 수 있다. 예를 들면 도트 그래픽 삼국지 게임을 만들려고 할 때 거기에 사용할 삼국지 무장 캐릭터들의 도트 일러스트를 만들어 달라고 하는 것과 같은 Task를 주더라도 잘 수행한다. 같은 것은 아니지만 https://agentgpt.reworkd.ai/ko에서 웹상에서 사용해볼 수 있다.
7. 추천 모델
정말 엄청나게 많은 모델들이 쏟아져 나왔고, 지금도 나오고 있기 때문에 어떤 모델을 사용해보는게 좋을지 복잡하게 느껴질때가 있다. LLM 벤치마크도 있지만 벤치마크마다 모델들의 순위가 꽤 다르기도 하고, 실제 체감하는 성능과 벤치마크가 다른 경우들도 꽤 있다. 여기서는 개인적으로 추천하는 모델들을 써보려고 한다. 여기서는 모델의 특징적인 부분만 쓰겠다. 모델에 대한 자세한 내용은 모델 이름에 링크된 페이지로 들어가면 확인할 수 있다.
7-1) MPT
- 개인적으로 MPT 모델은 모델 코드를 보는 것만으로도 많이 공부가 된다고 생각한다. 현 시점에서 좋은 성능을 보여주는 최신 조합들을 잘 사용했다.
- 상업적 사용 가능
- 학습 데이터 1T token으로 pre-train
- Flash Attention, Flash Attention with triton
- ALiBi
- 7B, 30B
7-2) Falcon
- 상업적 사용 가능
- 학습 데이터 1T token으로 pre-train
- Flash Attention
- Multi query Attention
- 현 huggingface의 llm 리더보드 SOTA
7-3)WizardLM 13B
- 상업적 사용 불가능, 학술적으로는 가능
- 모델 사이즈 대비 좋은 성능
7-4)Polyglot
- 한국어 가능
- 모델을 만드신 현웅님의 말에 따르면 현재 공개된 v1은 3개월 동안 급하게 만들어져서 아쉬움이 있고, 추후 공개될 v2는 한국어, 영어, 코드 데이터가 고르게 구성된 데이터로 pre-train하실 예정이라고 하니 v2가 기대된다. v1은 아직 성능적으로 좀 아쉬운 부분이 있다.
8. 프롬프트 엔지니어링
프롬프트 엔지니어라는 직군도 생겼을 정도로 LLM의 성능이 좋아지면서 프롬프트 엔지니어링도 이슈가 됐다. 사실 GPT4가 나왔을 때 3.5에 비해서 대충 말해도 충분히 좋은 결과를 만들어주는 경우가 보여서 모델 성능이 좋아지면서 점점 덜 중요해지지 않을까? 라고 생각했었는데 GPT4는 API를 사용해도 여전히 속도 이슈가 있고 가격차이도 무시하기 어렵다. 때문에 LLM을 서비스에 적용한다면 프롬프트 엔지니어링에 대한 기본적인 내용들은 숙지하는게 필요하다고 생각한다.
앤드류응의 https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/의 강의도 있다.
구분자로 ` ` `를 추천하는 것과 같은 디테일한 부분에서의 내용도 생각해볼만하고, 명확하게 요구 사항을 정의하는 것이나 답변의 형식을 정해주는 것도 중요하지만, 개인적으로는 스텝을 정의해서 COT와 비슷하게 Auto-regressive한 모델이 더 좋은 답변을 만들도록 유도하는 전략이 중요하다고 생각한다. 그만큼 답변 포맷을 만들어서 연계하는게 더 까다로워지긴하지만 속도 이슈로 3.5를 쓰게 될 때는 이러한 프롬프트 엔지니어링이 꽤 답변의 퀄리티를 바꿀 수 있다는 것을 확인해볼 수 있었다.
9. 결론
지금까지 LLaMA와 함께 최근의 LLM 상황들에 대해서 지금까지 느껴온 것들을 전반적으로 정리해봤다. 다양한 것들이 많이 쏟아지기도 했고 업무와 직접 연관이 없는 경우는 챙겨볼 시간이 없어서 제대로 이해하지 못한 부분들도 있어서 차근차근 정리해나갈 예정이다. 점점 모델의 활용이 더 중요하겠지만 그럼에도 아직까지는 이런 모델들의 전반적인 트렌드를 알아 두는 게 커리어적으로나 내 실력에 있어서나 중요하다고 생각한다.
레퍼런스
https://devocean.sk.com/blog/techBoardDetail.do?ID=164601&boardType=techBlog
'LLM' 카테고리의 다른 글
| LLaMA 2 살펴보기(작성 중)/08.27 업데이트 (0) | 2023.07.19 |
|---|